13. Memory management and pointers
13.1. Memory
Most of the computers we use today have memory to store data for processing. The data stored in memory needs to be stored and retrieved, for which we need an address. As an analog, you can think of a large library where books are kept in a shelf within their own cells. In our analog, the computer memory would be the shelf, the book will be data and the location of the cell in the shelf would be the memory address. A pointer in this case would be a variable that holds the memory address. Computer memory addresses are usually integers with its size (number of bits representing the address) depending on the computer architecture.
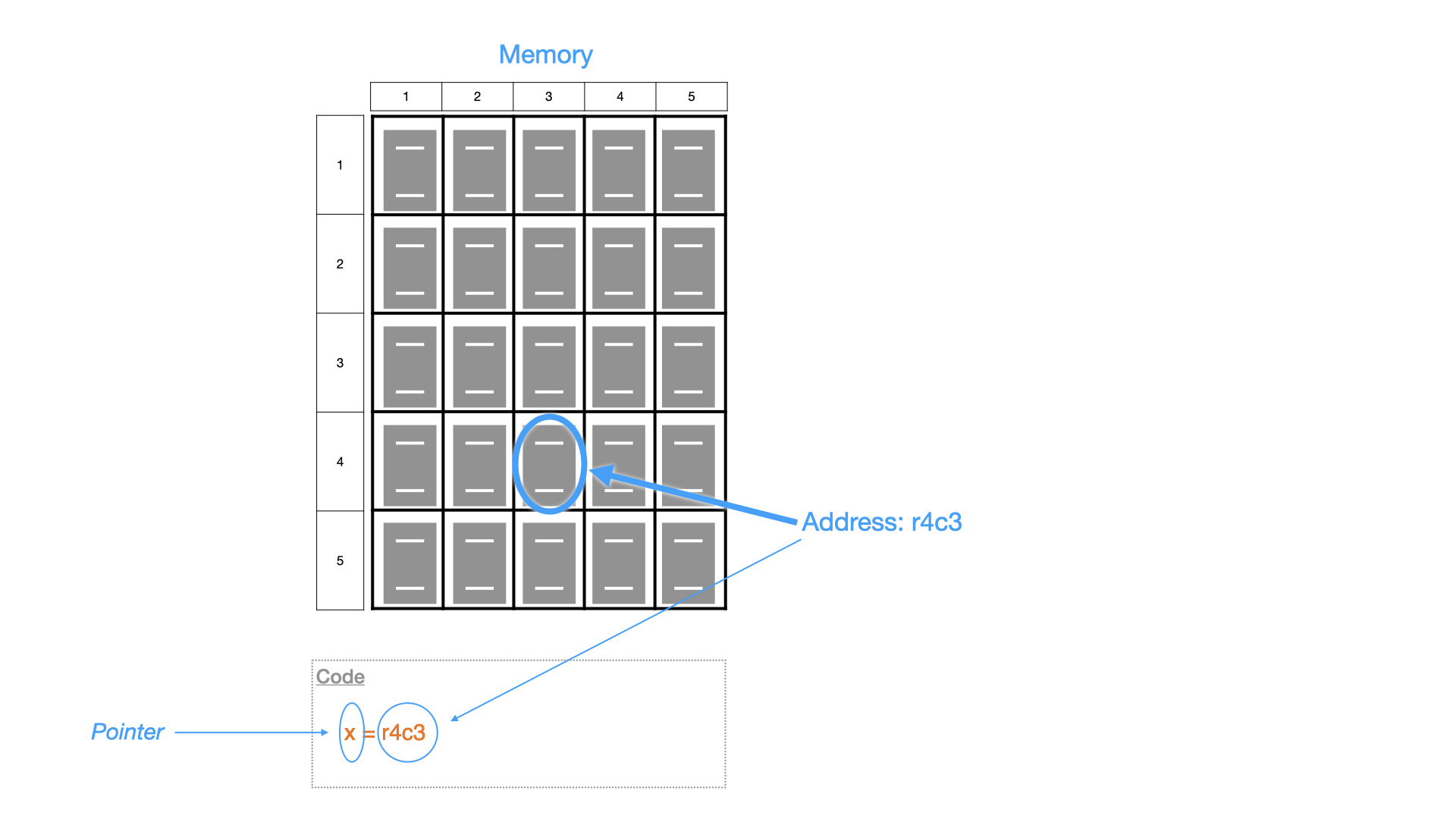
Here in the diagram the address of a cell containing the book we want is represented as row 4, column 3.
A computer memory is typically divided into many parts, of which the stack and heap are relevant for us.
13.1.1. Stack
When we are at a library, we usually fetch a book and then read it at a desk. In a way, the "read operation" happens at the desk. Similarly, when a thread is instantiated for execution, it is assigned a "working space" from the computer memory, known as stack. Within a thread, multiple functions may be getting called. When a function is instantiated for execution, it is assigned a block out of the stack called stack frame.
The stack frame will contain within it the function’s location, any values used within that function, inputs given to the function, etc. Once the function has completed its execution, the whole stack frame will be cleared. Once the stack frame is cleared, its memory would be reused for other functions getting instantiated. Stacks have a well defined lifecycle and the allocation and de-allocation of memory is automatically managed. This means that the programmer does not have to worry about allocating the memory and de-allocating the memory of stack-stored variables that he uses in code.
When a function calls another function, two stack frames gets created. Naturally, the outer function’s stack frame has a longer lifetime than the inner function’s stack frame (the inner functions completes execution and its stack frame is cleared, while the outer function is still running and its stack frame is still in use).
One requirement when allocating memory for a stack frame is that the compiler needs to know how much to allocate for the stack frame at the compile time itself. This is because stack frame is a pre-allocated memory, and it needs to allocate enough so that the function’s local variables can fit in. This means that we cannot place within a stack those data structures that do not know their size at compile time.
13.1.2. Heap
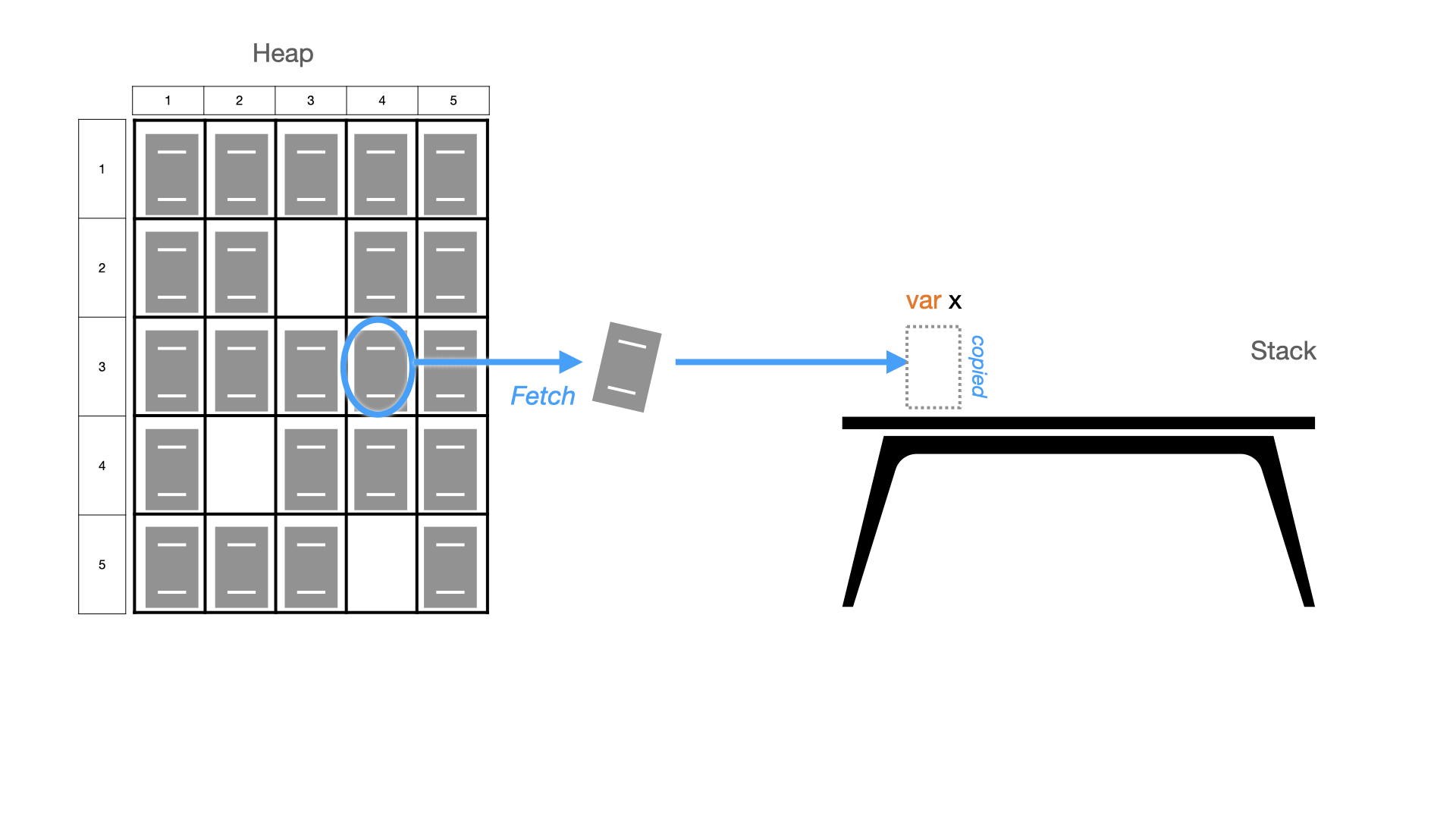
Since a stack cannot store data structures that do not know their size at compile time (e.g. a list that dynamically grows at runtime when data is added to it), we use a heap.
When data is stored in heap, the programmer usually keeps the address where it is stored in a variable (pointer) for future reference. Since a pointer size is well known already at compile time, we can store that pointer in the stack frame. Functions always work with stack frames, and sometimes we need to copy the data from heap into stack.
13.1.3. Memory management
Since memory is a finite resource, we need to manage it very carefully. Additionally, since programs rely on the integrity of the data it works with, care must be taken that the programs work with data that has a well defined lifecycle.
Allocation and de-allocation
If we allocate space in memory for our data and we forget to de-allocate after our use, memory would be "wasted". If it happens quite often during the runtime of the program, the program would reach a point where all the memory is exhausted and it has to abruptly quit. Therefore, we need to ensure to de-allocate memory after use.
Concurrent mutation
If we have a pointer to a memory location and if its data is mutated/modified by another function without us knowing, we would end up with "corrupted" data. This means that we need to ensure that the mutation of data is done only by one function at a time and it is clear at any point of time which function is doing the mutation. Many programming languages do not track such cases.
Lifetime and ownership
Management of memory becomes easier when we define within a program the lifetime (for how long it stays in memory) of a value and which part of the program owns the responsibility for its de-allocation and cleanup. In case a data structure has other data within it (e.g. list), then typically the container data structure is responsible for the de-allocation of data stored within it, and usually the container’s lifetime is the maximum lifetime of the contained data.
Most of the programming languages do not make lifetimes explicit and therefore programmers need to have a mental model of how long a piece of data lives. Problems occur when this mental model is wrong, resulting in crashes, or security issues. For example, if a pointer to data stored within an array is kept and if that pointer is not discarded when the array is de-allocated, then the pointer refers to an address that contains random data. This is known as a dangling pointer.
Since stack has a well defined lifecycle management, most of the memory management issues come up when we work with the heap.
Mojo provides excellent support for tracking both concurrent mutation and lifetime of values through built-in support for references.
13.2. Pointers in Mojo
Mojo provides many types of pointers to work with heap allocated data. Each pointer type has its own use cases and trade-offs.
13.2.1. Unsafe Pointer
In order to allocate memory from the heap, we use pointer operations like alloc and free. Mojo provides UnsafePointer type for manually managed pointers. The type is explicitly named as unsafe, to indicate that Mojo would not be managing the lifetime of the value pointed by the UnsafePointer. Programmers must take care to ensure that UnsafePointer is carefully managed.
An example is shown in the following code listing.
from memory import UnsafePointer
struct A(Movable, ImplicitlyCopyable):
var val: Int
fn __init__(out self, val: Int):
self.val = val
fn __copyinit__(out self, other: Self):
self.val = other.val
fn __moveinit__(out self, deinit other: Self):
self.val = other.val
def print_pointer(p: UnsafePointer[A]):
print(p)
def print_value(p: UnsafePointer[A]):
print(p[].val) # De-reference the pointer and then get the `val` field
Usage:
var x: UnsafePointer[A] = UnsafePointer[A].alloc(1) # Allocate space to store one instance of `A`
print_pointer(x) # Prints hexa decimal representation of the address within `x`
x.init_pointee_move(A(10)) # Initialize the location
print_value(x)
x.destroy_pointee() # Destroy the value before trying to free the memory
x.free() # Frees the memory pointed by `x`Here we see that a memory storage for type A is allocated on the heap using alloc. You can think of alloc allocating an array with length specified by the count argument. The count is the number of items of type A planned to be stored in that memory storage. The alloc method calculates the size of the type A and then allocate the total number of bytes for it. The space is initialized with value using init_pointee_move. The init_pointee_move expects its argument to implement the trait Movable, which indicates that the value can be safely moved to another location.
Mojo stores the value in the allocated memory storage contiguously. In order to get to the initialized value, we use the de-reference operator []. You can think of the de-reference operator as array subscript getting the first element of an array (actually p[0] would also work, but is discouraged). Before freeing the memory used by a value, we must call destroy_pointee, to ensure that all the related resources are also freed. Otherwise we would face a memory leak. Later we de-allocate the space using the free method of UnsafePointer.
On a quick look the above code seems to be simple and easy to reason, where the memory is allocated and freed. However, there is a potential memory leak. This would happen if the print_pointer or print_value throws an exception and the function exits early because of that. When that happens, the free will not get executed and the allocated memory in the heap would not be returned to the heap. This would lead to a memory leak, or worse, a security issue because now the data is available to potentially malicious code.
In the following code listing we see that the memory is freed in all cases, including errors.
from memory import UnsafePointer
struct A(Movable, ImplicitlyCopyable):
var val: Int
fn __init__(out self, val: Int):
self.val = val
fn __copyinit__(out self, other: Self):
self.val = other.val
fn __moveinit__(out self, deinit other: Self):
self.val = other.val
def print_pointer(p: UnsafePointer[A]):
print(p)
def print_value(p: UnsafePointer[A]):
print(p[].val) # De-reference the pointer and then get the `val` field
Usage:
var y: UnsafePointer[A] = UnsafePointer[A].alloc(1)
try:
y.init_pointee_move(A(10))
print_pointer(y)
finally:
y.destroy_pointee() # Destroy the value even in case of exception
y.free() # Free the memory even in case of exceptionWhat if we already have an instantiated value and wanted to find its address? The UnsafePointer provides __int__ method which can be used with Int() constructor to convert the pointer to an integer representation of the address.
from memory import UnsafePointer
struct A(Movable, ImplicitlyCopyable):
var val: Int
fn __init__(out self, val: Int):
self.val = val
fn __copyinit__(out self, other: Self):
self.val = other.val
fn __moveinit__(out self, deinit other: Self):
self.val = other.val
def print_pointer(p: UnsafePointer[A]):
print(p)
def print_value(p: UnsafePointer[A]):
print(p[].val) # De-reference the pointer and then get the `val` field
Usage:
var a_instance = A(12)
var z: UnsafePointer[A] = UnsafePointer[A](to=a_instance)
print_pointer(z)As mentioned earlier, care should be taken to understand the lifecycle of the value before passing its address. For example, returning the address of a value allocated on a stack frame to the callee stack frame would most likely result in a dangling pointer. Since Mojo destructs value on last use, it is also necessary to keep the value alive until the pointer’s purpose is completed, otherwise we have a pointer that points to an uninitialized memory since the value was already destructed.
Mojo also provides another option to initialize an allocated memory, using init_pointee_copy. The difference is that the init_pointee_move moves the value to the allocated space, while the init_pointee_copy just copies the value, leaving the original value intact.
from memory import UnsafePointer
struct A(Movable, ImplicitlyCopyable):
var val: Int
fn __init__(out self, val: Int):
self.val = val
fn __copyinit__(out self, other: Self):
self.val = other.val
fn __moveinit__(out self, deinit other: Self):
self.val = other.val
def print_pointer(p: UnsafePointer[A]):
print(p)
def print_value(p: UnsafePointer[A]):
print(p[].val) # De-reference the pointer and then get the `val` field
Usage:
var a: UnsafePointer[A] = UnsafePointer[A].alloc(1)
a.init_pointee_copy(A(11)) # Initialize the location
print_value(a)
...It is also possible that we end up in a situation where two pointers are pointing to the same value. In this case, when a pointer is used to modify the value, the other pointer automatically refers to the modified value. In some case it may be intentional from the programmer’s side. However, in most cases, it results in defects that are hard to track and fix.
var another_a = A(100)
var i: UnsafePointer[A] = UnsafePointer[A](to=another_a)
var j: UnsafePointer[A] = UnsafePointer[A](to=another_a) # Pointer aliased
print(i[].val) # Prints 100
i[].val += 10
print(j[].val) # Prints 110In the above example, two pointers were pointing to the same value. When one pointer was used to update the value, the other pointer picked up the updated value. This code is a simple one and it is easy to detect what is happening. However in large code bases especially in multi-threaded scenarios, such cases result in hard to find defects.
All bets are off when we use UnsafePointer. Mojo does not track what goes on with its usage. This is by design. UnsafePointer is useful for those cases where the application needs to work intimately with the hardware or the operating system. Therefore, use it with care.
If pointers are such a pain, then why do we use it?
13.2.2. ARC Pointer
As you have already seen, managing values on the heap requires a lot of care. Some programming languages make it easy to manage values allocated on the heap through the use of a garbage collector. A garbage collector keeps track of values on the heap and as soon as it determines that nothing is using it, it will automatically clear the value and its associated memory (the unused value is the "garbage"). There are different approaches to garbage collection. One of them is reference counting.
Mojo has a reference counted pointer named as ArcPointer. The ArcPointer keeps the count of its copies in use. If an ArcPointer pointer is created, and it is then passed to another function as a copy while sharing the same underlying value, the ArcPointer will increment its count. When all the ArcPointer pointers to that value is destructed, the count becomes zero and the underlying value will also be destructed and its memory cleared.
from memory import ArcPointer
var arcp = ArcPointer(A(200))
# Reference count is 1
var arcp2 = arcp # Reference count increased with this copy
# Count is now 2 as `arcp` is copied to new `ArcPointer` called `arcp2`
print(arcp[].val) # Prints 200
arcp[].val += 10
# Count is now 1 as `arcp` is cleared as the above line was its last use
print(arcp2[].val) # Prints 210
# Value is cleared from memoryArcPointer solves de-allocation issues we saw earlier by piggy backing on Mojo compiler’s eager destruction of values on the stack frame. However, it does not solve other issues like concurrent mutation.
13.3. Pointer
If ArcPointer keeps a runtime record of its copies so as to ensure that the value is destructed when it is no longer needed, Pointer helps Mojo compiler to track it at compile-time.
The Pointer type takes in an Origin parameter, which is then tracked across assignments and moves. This tracking by the compiler ensures that the value pointed by Pointer lives at least as long as the pointer being used, preventing dangling pointers.
The Pointer type in Mojo is always derived from a preexisting value, unlike UnsafePointer that can exist independent of the value (e.g. null pointers are impossible in Pointer). The Mojo compiler also does not allow replacing values referred by the Pointer with another value.
from memory.pointer import Pointer
struct A:
var val: Int
fn __init__(out self, val: Int):
self.val = val
def print_value(p: Pointer[A]):
print("print_value called for val:", p[].val)
print(p[].val) # De-reference the reference and then get the `val` field
Usage:
var a_instance = A(12)
var ref_a = Pointer(to=a_instance) # Construct a Pointer out of an existing value
print_value(ref_a) # Prints 12Origin gets transferred over to copies of the pointer.
from memory.pointer import Pointer
struct A:
var val: Int
fn __init__(out self, val: Int):
self.val = val
def print_value(p: Pointer[A]):
print("print_value called for val:", p[].val)
print(p[].val) # De-reference the reference and then get the `val` field
Usage:
var a_instance = A(12)
var ref_a = Pointer(to=a_instance) # Construct a Pointer out of an existing value
print_value(ref_a) # Prints 12
var ref_a2 = ref_a # The same origin is copied onto the new pointer too
ref_a2[].val = 13 # De-reference and assign value
print_value(ref_a2) # Prints 13Mojo ensures that even though the pointer data types are the same (Pointer[A]) they are not assignable to each other because Origin is part of the pointer’s essence. Origin is not exactly a type, but rather a dynamic property of the underlying value of the pointer.
from memory.pointer import Pointer
struct A:
var val: Int
fn __init__(out self, val: Int):
self.val = val
def print_value(p: Pointer[A]):
print("print_value called for val:", p[].val)
print(p[].val) # De-reference the reference and then get the `val` field
Usage:
var a_instance = A(12)
var ref_a = Pointer(to=a_instance) # Construct a Pointer out of an existing value
print_value(ref_a) # Prints 12
var another_instance = A(14)
var ref_another_a = Pointer(to=another_instance)
# ref_another_a = ref_a # Uncommenting this would result in compilation error.
print_value(ref_another_a)Functions in mojo take arguments as read-only by default. This extends to origins also. A mutable origin will automatically become an immutable one when taken as a function argument.
from memory.pointer import Pointer
struct A:
var val: Int
fn __init__(out self, val: Int):
self.val = val
def print_value(p: Pointer[A]):
print("print_value called for val:", p[].val)
print(p[].val) # De-reference the reference and then get the `val` field
Usage:
var a_instance = A(12)
var ref_a = Pointer(to=a_instance) # Construct a Pointer out of an existing value
print_value(ref_a) # Prints 12
def change_value(p: Pointer[A]):
print(p[].val)
#p[] = 16 # Uncommenting this would result in compilation error.
...
change_value(ref_a)
ref_a[].val = 15 # WorksIn the previous code listing the ref_a has a mutable origin, but when it is passed in to change_value, it is turned into an immutable origin. While we can print its value (i.e., read), we cannot change its value as it is immutable.
What if we really wanted to pass a mutable pointer to the function? The answer to this lies in MutableOrigin. With MutableOrigin we are indicating to the compiler to not convert the mutable origin carried by the pointer to an immutable one.
from memory.pointer import Pointer
struct A:
var val: Int
fn __init__(out self, val: Int):
self.val = val
def print_value(p: Pointer[A]):
print("print_value called for val:", p[].val)
print(p[].val) # De-reference the reference and then get the `val` field
Usage:
var a_instance = A(12)
var ref_a = Pointer(to=a_instance) # Construct a Pointer out of an existing value
print_value(ref_a) # Prints 12
def change_value2[origin: MutableOrigin](p: Pointer[A, origin=origin]):
p[] = A(16) # Now it works
...
change_value2(ref_a)
print(ref_a[].val) # Prints 16Here we are taking a MutableOrigin as parameter, which is then passed on to the pointer. The compiler would then preserve the original mutability of the pointer.
Most of the pointer use cases can be solved using Pointer. However, in some low-level programming scenarios, we may need to use UnsafePointer for fine-grained control.
13.3.1. OwnedPointer
In order to ensure a proper management of memory, it is necessary to have clarity on who owns the responsibility of de-allocating a value. In Mojo, the OwnedPointer type is used to indicate that the pointer owns the value it points to. When an OwnedPointer is destructed, it will also destruct the underlying value and free its memory. Such type of pointers are also known as smart pointers.
from memory.owned_pointer import OwnedPointer
from memory.unsafe_pointer import UnsafePointer
struct A(Movable, ImplicitlyCopyable):
var val: Int
fn __init__(out self, val: Int):
self.val = val
def print_value(p: OwnedPointer[A]):
print("print_value called for val:", p[].val)
print(p[].val) # De-reference the reference and then get the `val` field
Usage:
var a_instance = A(12)
var ref_a = OwnedPointer(a_instance^) # Move the value into an OwnedPointer
print_value(ref_a) # Prints 12
# print(a_instance.val) # Original instance is no longer usable. Uncommenting this would result in compilation error.OwnedPointer can be constructed in two ways. One is by moving an existing value into the pointer as shown above, and the other is by copying an existing value into the pointer. In the first case, the original value is no longer usable, while in the second case, the original value remains usable.
Usage:
var b_instance = A(13)
var ref_b = OwnedPointer(b_instance) # Copy the value into an OwnedPointer
print_value(ref_b) # Prints 13
print(b_instance.val) # Original instance is still usable