21. GPU programming
Graphics processing unit (GPU in short form) is a specialized hardware designed to accelerate computation for graphics rendering and parallel processing tasks. Though initially developed for rendering images and videos, GPUs have evolved to become powerful tools for general-purpose computing, particularly in fields such as machine learning, scientific simulations, and data processing. GPUs are able to perform many calculations simultaneously, making them well-suited for tasks that can be parallelized.
CUDA from NVIDIA is a widely used platform for GPU programming. CUDA provides a parallel computing platform and application programming interface (API) that allows developers to harness the power of NVIDIA GPUs for general-purpose computing. CUDA is NVIDIA-specific, but there are other models (e.g., OpenCL, SYCL, ROCm) for different hardware. Mojo aims to provide a more general and flexible approach to GPU programming that can work across different hardware platforms. It borrows some of the concepts from CUDA but is not tied to any specific vendor.
The core concepts in GPU programming include:
-
Kernels: Kernels are functions that are executed on the GPU and are designed to be executed in parallel across many threads. In case of CUDA, kernels are defined using an extension of C++. Mojo allows defining kernels using normal functions. Note that in general computing terminology, a kernel refers to the central part of an operating system that manages system resources and hardware interactions. However, in the context of GPU programming, a kernel specifically refers to a function that runs on the GPU.
-
Threads: Threads are the basic units of execution on a GPU. A kernel is launched with a grid of threads, where each thread executes the kernel function independently. Threads can be organized into blocks and grids to facilitate parallel execution.
-
Blocks: Blocks are groups of threads that can work together and share data through shared memory. Each block is executed independently, and multiple blocks can be launched in parallel to utilize the GPU’s resources effectively.
-
Grids: Grids are collections of blocks that are launched to execute a kernel. The grid size determines the total number of threads that will be executed on the GPU.
-
Memory Management: GPUs have their own memory hierarchy, which includes global memory, shared memory, local memory, constant memory, and texture memory.
Threads and blocks are organized in a 3 dimensional structure to allow for more complex data processing patterns (to be specific, it can be 1D, 2D, or 3D depending on the hardware). The following diagram illustrates the relationship between threads, blocks, and grids in GPU programming.
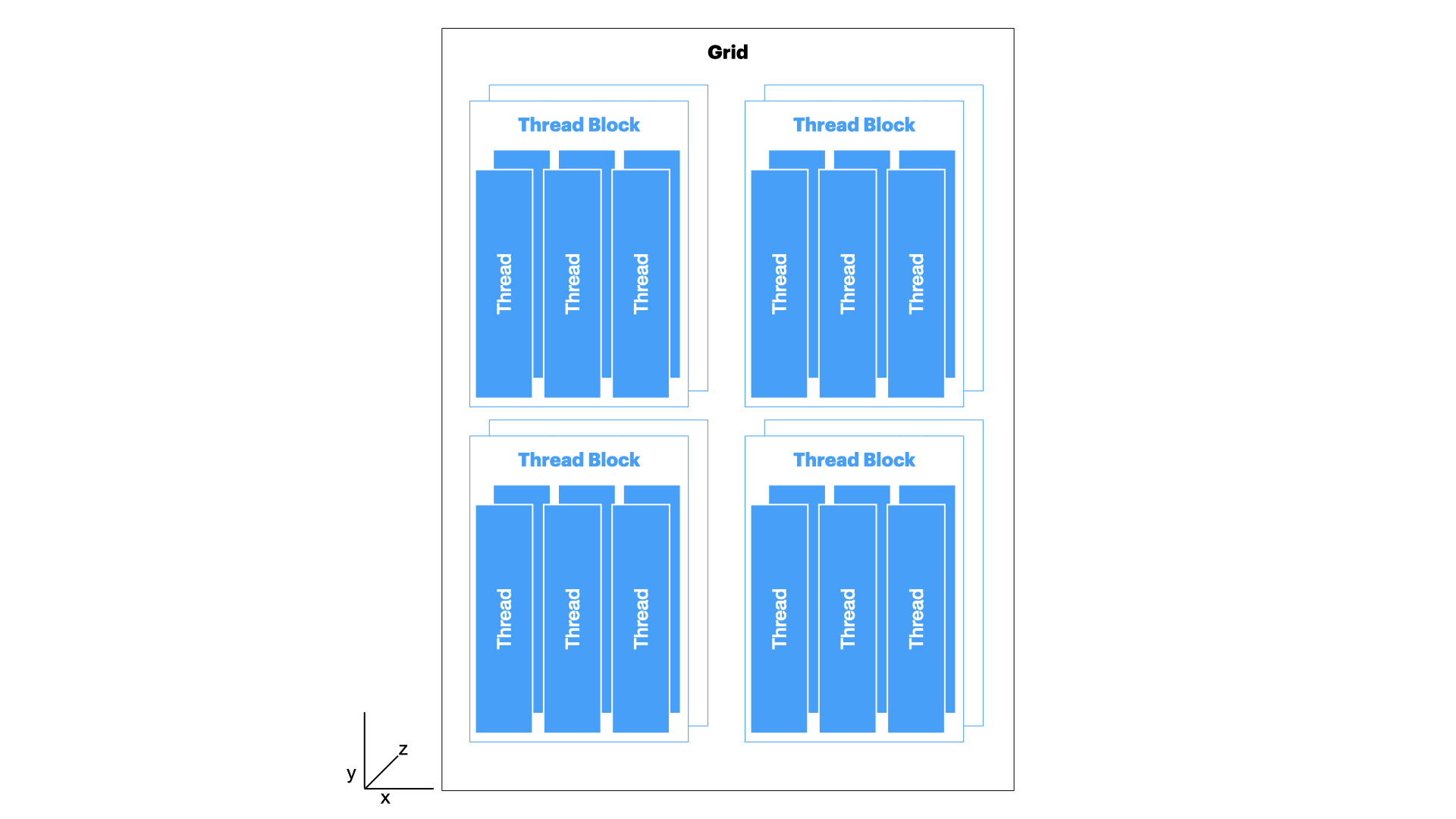
In the above diagram we can see that a 3 dimensional thread and block structure that is mapped to a single grid. There can be multiple such grids launched to execute kernels. A single kernal is assigned to a single grid. The parallel execution happens at the thread level within blocks and across blocks within a grid.
When we define a program, we can specify how many threads and blocks we want to use for executing a kernel. This allows us to control the level of parallelism and optimize performance based on the specific hardware capabilities of the GPU.
When you program a GPU, you typically write code that defines the kernel functions and specifies how they should be executed on the GPU. The code meant for the GPU is known as device code, while the code that runs on the CPU is known as host code. The host code is responsible for managing memory transfers between the CPU and GPU, launching kernels, and handling synchronization. In simple terms, we are sending both code and data to the GPU for execution and then fetch the results back.
from std.gpu import thread_idx, block_idx
from std.gpu.host import DeviceContext, DeviceBuffer, HostBuffer
from layout import Layout, LayoutTensor
from std.memory import UnsafePointer
comptime data_type = DType.int32 # Data type of the buffer elements
comptime no_of_blocks = 8 # How many blocks within the grid
comptime no_of_threads = 8 # How many threads within each block
comptime total_possible_elements = no_of_blocks * no_of_threads # Total elements in the tensor
def add_two(result: UnsafePointer[Scalar[data_type], MutAnyOrigin], first: UnsafePointer[Scalar[data_type], MutAnyOrigin], second: UnsafePointer[Scalar[data_type], MutAnyOrigin]): # A kernel function
index = block_idx.x * no_of_threads + thread_idx.x # Calculate the global index
result[index] += first[index] + second[index]
def main() raises:
with DeviceContext() as ctx: # Create a context for the default GPU device
var result_buf = ctx.enqueue_create_buffer[data_type](total_possible_elements) # Create result buffer on the device's memory
result_buf.enqueue_fill(0) # Initialize the device result_buffer with zeros
var input_buf1 = ctx.enqueue_create_buffer[data_type](total_possible_elements) # Create first input buffer on the device's memory
input_buf1.enqueue_fill(10) # Initialize the device first buffer with 10s
var input_buf2 = ctx.enqueue_create_buffer[data_type](total_possible_elements) # Create second input buffer on the device's memory
input_buf2.enqueue_fill(20) # Initialize the device second buffer with 20s
with result_buf.map_to_host() as host_result_buf: # Map the device buffers to host buffers to print
print(host_result_buf) # Show the contents of the host result_buffer
var compiled_fn = ctx.compile_function[add_two]() # Compile the kernel function for the device
ctx.enqueue_function(
compiled_fn,
result_buf,
input_buf1,
input_buf2,
grid_dim=no_of_blocks,
block_dim=no_of_threads
) # Launch the kernel
ctx.synchronize() # Wait for the kernel to complete
with result_buf.map_to_host() as host_result_buf: # Again map the device result_buffer to host result_buffer to get the data back
print(host_result_buf) # Show the contents of the host result_buffer after addition
Prints:
HostBuffer([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
HostBuffer([30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30])For the above code to run, ensure that you have the necessary GPU drivers and SDKs installed on your system. For example, in case of MacOS with Apple Silicon, ensure that you have the latest version of XCode installed which includes the Metal framework for GPU programming.
In the above code, we first define a kernel function add_two that takes two input buffers and an output buffer. Each thread calculates its unique index based on its block and thread IDs, and performs the addition operation on the corresponding elements from the input buffers, storing the result in the output buffer.
You may have noticed that when we need to print the contents of the buffers, we first map the device buffers to host buffers using the map_to_host() method. This is necessary because the GPU memory is separate from CPU memory and is not directly accessible from the CPU, so we need to create a mapping to read the data.